Cursor, Windsurf 等 LLM 辅助编程工具得到了大量关注。另一方面,很多工作其实并不会非常多涉及编程,即使是有数据处理,也会使用 Excel、SPSS等工具。但是与编程不同,这些专门工具在 LLM 上是缺乏预训练支持的,我也体验过几款 Sheet Copilot 工具,发现距离真正可用还有比较大的差距。
比如飞书的 Sheet Agent,也就是他们多维表格的 AI 助手,几乎很难做到按照指令办事,更多时候只能处理简单的指令,比如求和、加粗等,如果要处理复杂指令,比如
统计 2010-2020年间销售量的分布,并对两款商品的销量进行 T 检验,创建一个新的工作表承载这个结果。
基本上是做不到的,然而其实后者才是大家真正需要的能力。要实现 Sheet Agent 有两个思路
生成代码去操作。比如使用 openxlsx 等。这种方法的好处是,可以借助 LLM 本身学到的代码能力,表示能力可能会更强。但坏处是,我们得专门为代码去设计沙盒,也很难对生成的代码进行性能优化。比如刚刚举的例子,「统计 2010-2020年间销售量的分布,并对两款商品的销量进行 T 检验」,这里使用 Python + openxlsx ,LLM 可能会更倾向于使用 Python 代码去计算分布、进行 T 检验,而非利用产品本身的能力。为了加速计算,各家文档产品都会做一些性能优化,比如算子的编排,使用 script(无论是 Python 还是 vbs)都有可能引起性能的大幅下降。
生成操作序列。对于文档产品来说,所有的操作都可以被刻画为 mutation,这里的 mutation 就是对表格的原子操作,所有的操作都能被还原为 mutation 的序列。好处是这真的像用户自己的操作,因此兼容原有的所有基建。但难点是:1. 不同的产品有不同的 mutation 设计,LLM 是无法 zero-shot 感知这些信息的;2. LLM 无法严格按照既定的格式输出 mutation 序列;3. 缺乏 mutation 层面的数据集,现有的数据集都是表格文件层面的 input 和 output。
现有的模型基本上都是使用第一种方法进行处理。在我看来当前的研究存在下列难题:
- 缺乏真实数据:当前的 benchmark 量都比较小,数据表也非常小,操作序列也很简单。这些都是脱离真实场景的,比如很多 Agent 是直接把整个数据表喂给了 LLM,这在真实场景上是不可能的。
- 缺乏有效的评估手段:和其他的生成任务一样,Sheet 操作任务也缺乏有效的评估手段,比如两个同样错误的操作,如何去评估哪个错得更多?两个同样正确的操作,如何去评估谁的实现更好?
- 缺乏 mutation 层面的支持:正如上文所言,现实场景不可能涉及一个沙箱容器来执行特定的代码,一方面存在安全性问题,另一方面,这对于数据一致性、性能都是巨大的挑战。
SheetCopilot (NeurIPS 2023)
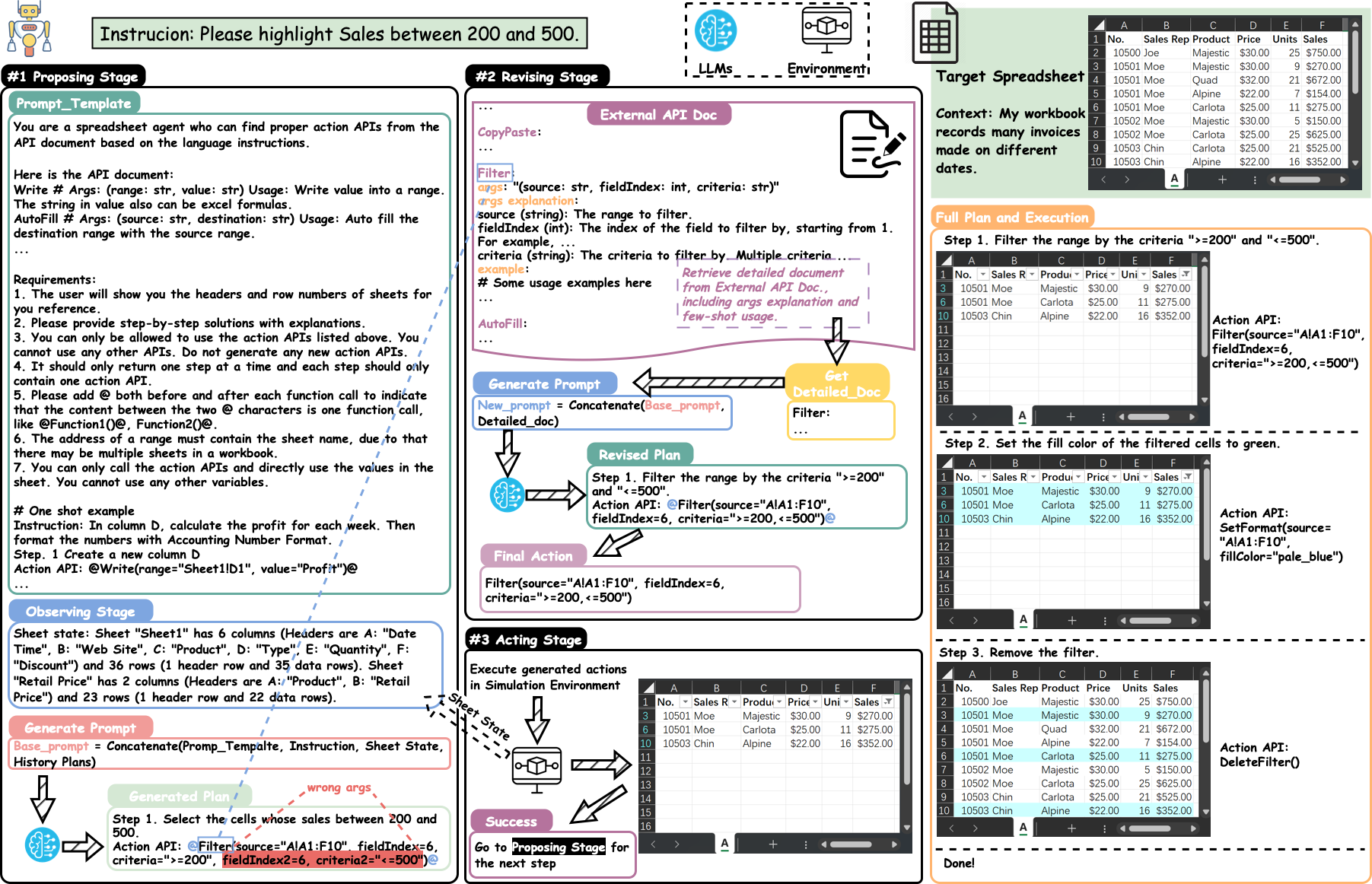
图 1:Sheet Copilot
SheetCopilot 是一个基于 LLM 的表格操作助手,它通过自然语言指令来控制电子表格软件。这篇文章的主要贡献在于:
- 设计了一套原子操作(atomic actions)作为电子表格软件功能的抽象,这里的原子操作也就是我们刚刚提到的 mutation。
- 提出了一个基于状态机的任务规划框架,使 LLM 能够稳定地与电子表格交互
- 构建了一个包含 221 个表格控制任务的数据集
- 建立了一个全自动的评估流程
在评估方面,SheetCopilot 在单次生成的情况下能够正确完成 44.3% 的任务,显著优于基于代码生成的基线方法。这个结果也说明了当前表格操作任务的难度。
具体来说,SheetCopilot 的原子操作包括:
- 单元格操作:读取、写入、格式化
- 行列操作:插入、删除、移动
- 工作表操作:创建、删除、重命名
- 公式操作:设置、修改、删除
- 图表操作:创建、修改、删除
这些原子操作被组织成一个层次化的结构,LLM 可以通过组合这些操作来完成复杂的任务。比如,要完成"计算 A 列的平均值并写入 B1 单元格"这个任务,LLM 需要:
- 读取 A 列的所有值
- 计算平均值
- 将结果写入 B1 单元格
但是可以观察到,这里的原子操作是严重简化的,比如缺乏对公式的支持、缺乏对图表具体操作的支持。
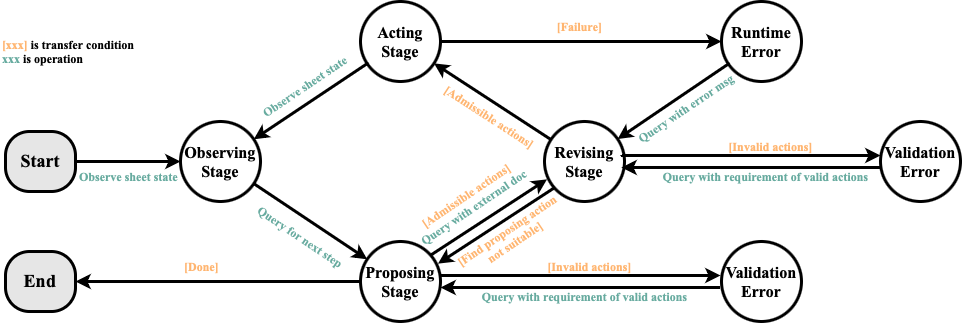
图 2:Sheet Copilot 的有限状态机
SheetCopilot 使用有限状态机来管理任务执行过程,包括以下状态:
- 初始化:解析用户指令,确定任务目标
- 规划:将任务分解为原子操作序列
- 执行:按顺序执行原子操作
- 验证:检查执行结果是否符合预期
- 修正:如果结果不符合预期,尝试修正
- 完成:任务成功完成
SpreadsheetBench(NeurIPS 2024)
SpreadsheetBench 是一个更具挑战性的表格操作基准测试,它的特点是:
- 数据集来源:包含 912 个来自真实场景的问题,这些问题是直接从在线 Excel 论坛收集的
- 数据多样性:包含了 2,729 个测试用例,每个指令平均有 3 个测试用例
- 任务类型:涵盖了查找、提取、求和、高亮、删除、修改、计数等多种操作类型
- 表格复杂度:包含了多表格、非标准关系表、丰富的非文本元素等
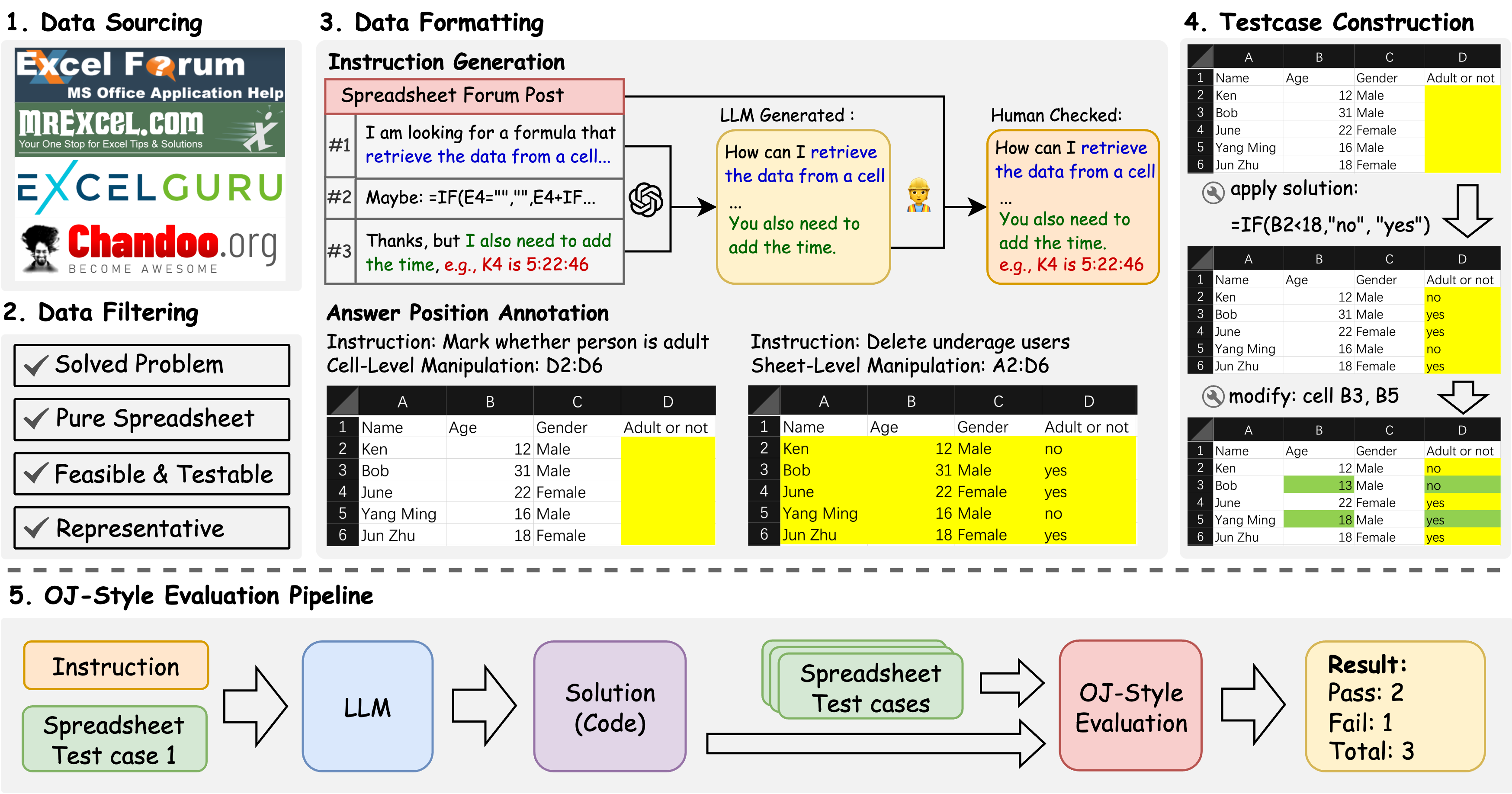
在评估方法上,SpreadsheetBench 采用了类似在线评测平台的评估方式,为每个指令创建多个测试用例,确保评估的是能够处理不同值表格的稳健解决方案。
具体来说,SpreadsheetBench 的评估指标包括:
- 执行正确性(Execution Correctness):检查操作序列是否能够正确执行
- 结果正确性(Result Correctness):检查最终结果是否符合预期
- 效率(Efficiency):评估操作序列的长度和复杂度
- 鲁棒性(Robustness):测试在不同输入数据下的表现
SheetAgent(WWW 2025)
SheetAgent 是一个专注于复杂表格推理和操作的自主代理。它的主要特点是:
- 模块化设计:包含三个协作模块:Planner(规划器)、Informer(信息提供者)和 Retriever(检索器)
- 迭代推理:通过迭代任务推理和反思来实现高级推理和准确的表格操作
- 性能提升:在多个基准测试上实现了 20-30% 的通过率提升
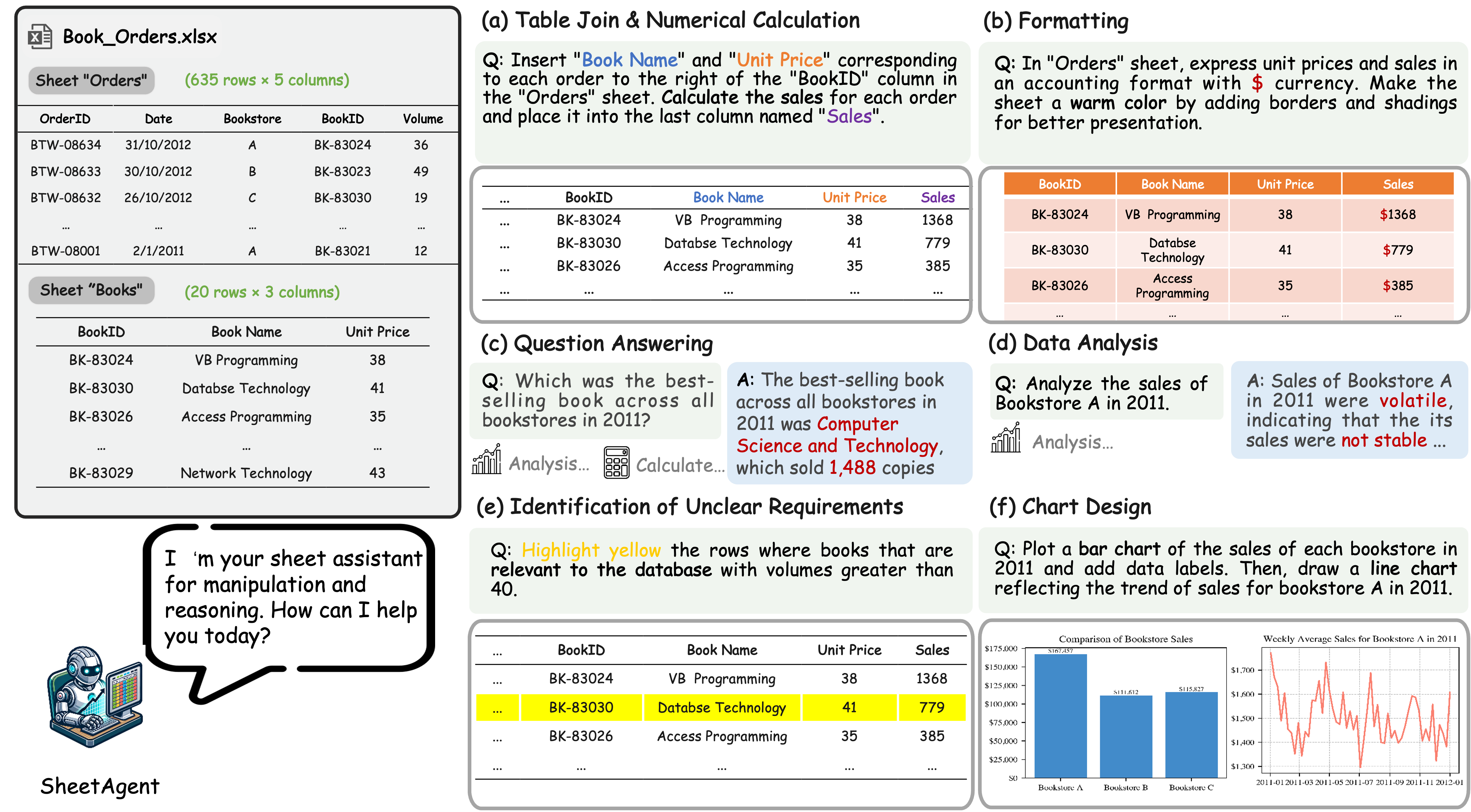
具体来说,SheetAgent 的三个核心模块:
Planner(规划器):
- 负责将用户指令分解为子任务
- 使用树形结构表示任务依赖关系
- 动态调整任务执行顺序
- 处理任务间的数据依赖
Informer(信息提供者):
- 分析表格结构和内容
- 提取关键信息和特征
- 识别数据模式和关系
- 提供上下文信息给其他模块
Retriever(检索器):
- 维护操作历史记录
- 检索相似的历史操作
- 提供操作建议和参考
- 优化操作序列
SheetAgent 能够处理多样化的表格推理和操作任务,包括:
- 可视化任务:创建各种类型的图表,支持自定义样式和布局
- 长序列和多步骤操作:处理复杂的多表操作和数据转换
- 需要一致推理能力的任务:处理数据依赖和约束条件
- 处理模糊需求的任务:通过交互式对话澄清用户意图
在实现上,SheetAgent 采用了以下技术:
- 多轮对话:通过对话历史理解用户意图
- 增量执行:支持边执行边反馈
- 错误恢复:自动检测和修复执行错误
- 性能优化:缓存中间结果,避免重复计算
这三个工作都试图解决表格操作中的核心问题,但采用了不同的方法。SheetCopilot 关注于原子操作的抽象和状态管理,SpreadsheetBench 致力于构建更真实的评估基准,而 SheetAgent 则专注于复杂推理和操作的自主性。这些工作共同推动了表格操作领域的发展,但正如我们之前讨论的,仍然存在许多挑战需要解决。
与 Coding Agent 不同,Sheet Agent 要求模型不仅能够有效处理任务,为了能被集成到现有的系统里,比如 Google Docs、Tencent Docs,Sheet Agent 还最好得产生 mutation 序列,而非使用 Script 对表格进行操作,如何把相关的知识注入 LLM ,如何限制 LLM 的输出严格符合 mutation 序列语法都是比较困难的问题。
在任务执行层面,因为把整个表格传给 LLM 是不科学的,如何使用 RAG 技术等去获取信息也是一个值得做的方向。
最为重要的是,如何想办法构造出大规模的真实数据集,是重中之重。要知道,现在的协同文档,很多都支持百万级别单元格,平均单元格数量应该也是至少在上千单元格这个层级,更别说现在的数据集只是在做一些最简单的任务,复杂任务:
- 公式利用的能力
- 复杂的图表操作
- 单元表之间的依赖管理
- 如何生成性能更优的操作序列 这些都需要更复杂,更庞大的真实数据集才能推动。