随着cursor等代码助手工具的兴起,代码生成与检索成为了研究的热点。本文介绍ACL 2024的三篇文章,这三篇文章都非常有意思,关注在代码生成与检索的统一表示上。
[ReCo] Rewriting the Code: A Simple Framework for Large Language Model Augmented Semantic Code Search
首先介绍的是ReCo,这篇文章提出了一个非常非常简单但是有效的方法,用LLM去「翻译」代码,统一代码的风格,然后再去做检索。它想解决的问题,其实就是语义搜索这个问题,比如
Query: 实现UserDAO的函数
以往我们去用类似双塔结构,直接尝试对齐 Query 和 Code 的 embedding,但是这其实很难,因为代码的结构和自然语言的结构非常不一样。比如这里的 Ground Truth 是:
class UserDAO {
constructor(private db: Database) {}
async findByEmail(email: string): Promise<User | null> {
const result = await this.db.query(`SELECT * FROM users WHERE email = $1`, [email]);
return result.rows[0] || null;
}
}
通过计算 Query 和 Code 的 embedding 的余弦相似度,$ \cos(q, c) $,来衡量 Query 和 Code 的相似度。之后,学者们提出了生成增强检索(Generative Augmented Retrieval, GAR),通过 LLM 生成更加准确的 Query,然后再去做检索。比如我们可以让 LLM 先自己根据 Query 生成对应的代码,再去计算 生成的代码片段 和 代码库中的代码片段 的相似度。这样就避免了自然语言和代码之间天然的差异。
ReCo 的在这之上多做了一步,也就是用 LLM 去「翻译」真实的代码,统一代码的风格,然后再去做检索。取得了不错的效果。
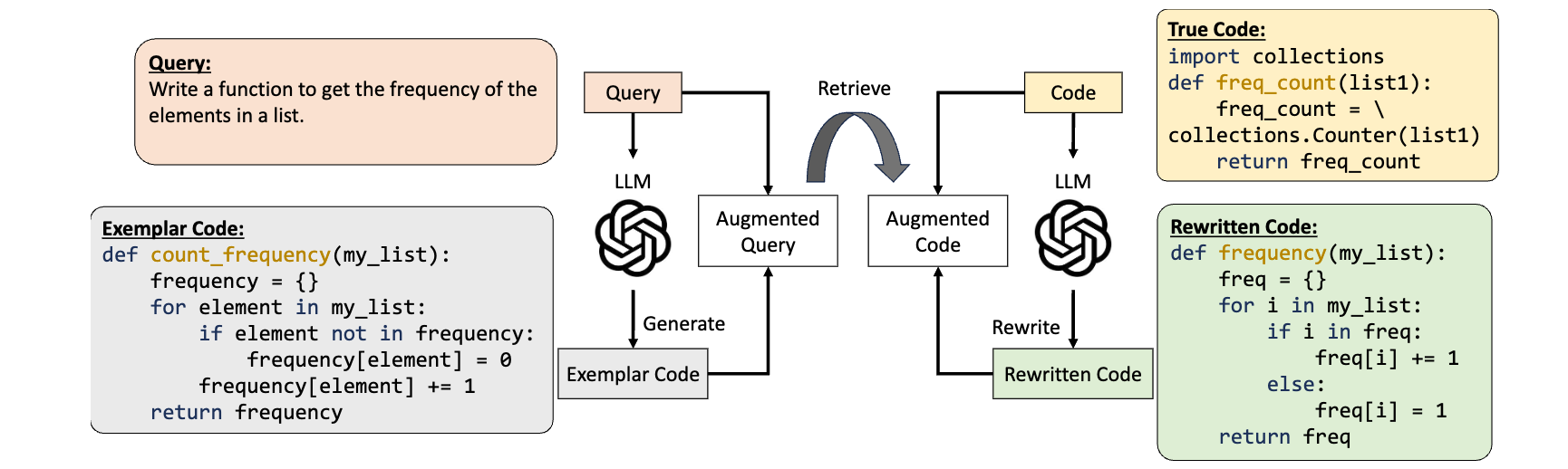
它的提升:
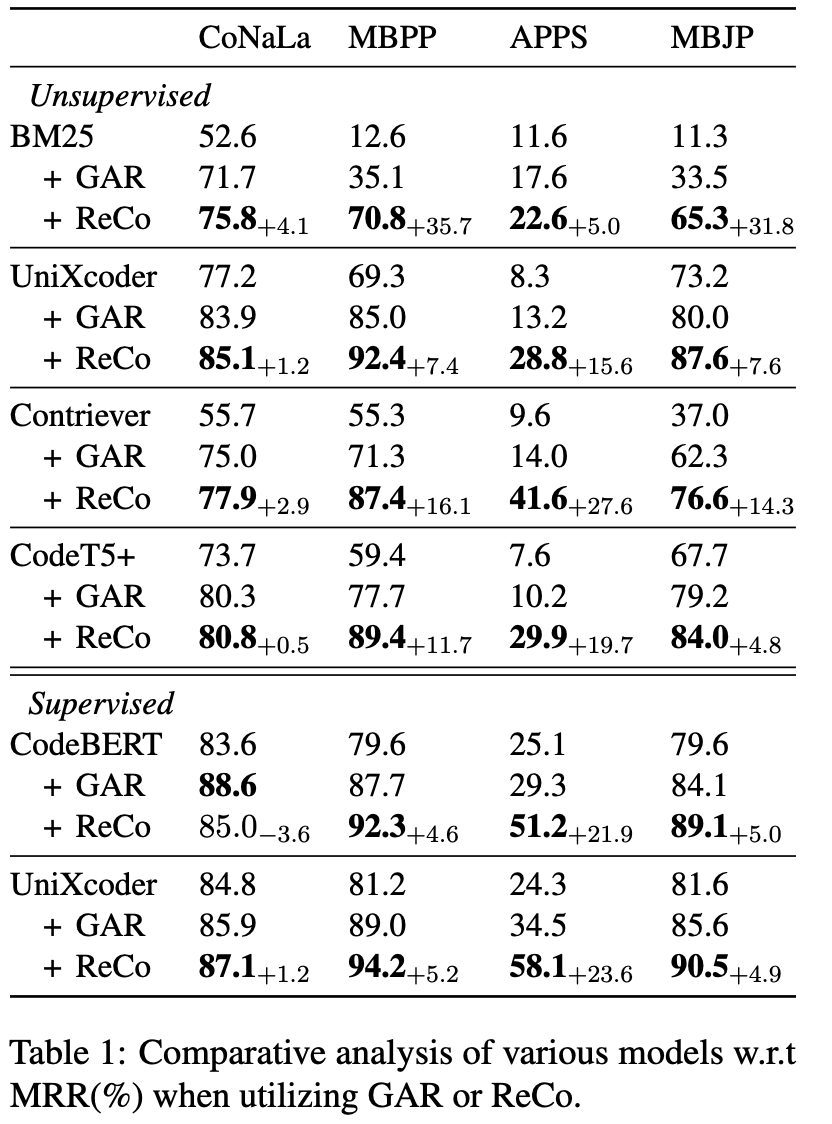
这个效果是非常显著的,在多个数据集上都有提升。这提示我们,代码风格的重要性。在实际开发中,我们会省略、复用、重构代码,这些行为都会导致代码风格的变化。LLM 翻译的这一步实际上就是把「省略」、「复用」、「重构」这些行为去掉。因为 LLM 生成辅助检索的代码是不会考虑这些行为的。
[UniCoder & IRCoder]
[IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators]
[UniCoder: Unified Code Representation for Code Generation and Retrieval] 这两篇论文有一个非常相似的视角,就是要找到一个中间介质去表示代码。不过 IRCoder 是用汇编语言去做这个介质,而 UniCoder 是用一个新的自定义的编程语言去做这个介质。
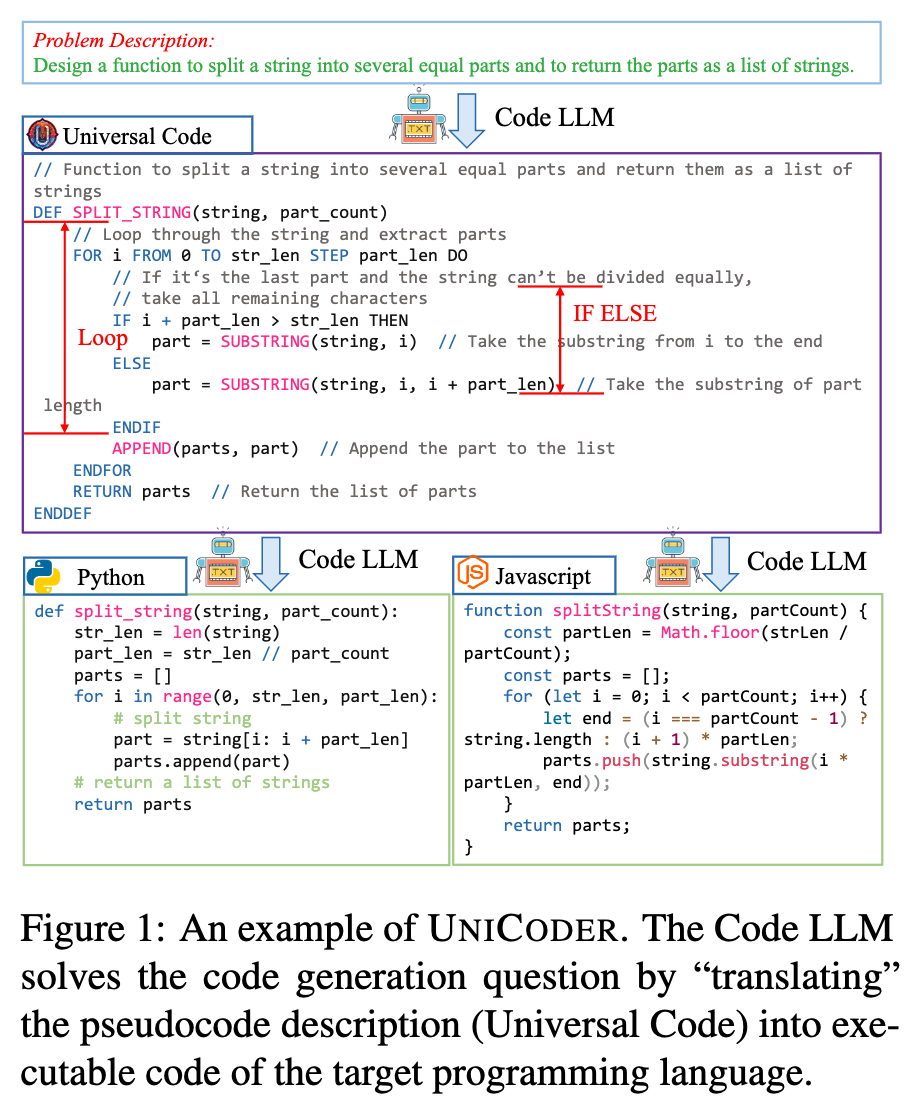

这件事情也非常值得我们思考,由于不同编程语言的语料分布不同,LLM 能够学到的表示是不同的。但另一方面,语言只是逻辑的翻译,如果我们能够把不同编程语言之间的能力、表示进行迁移,是可以提升 LLM 的泛化能力的。
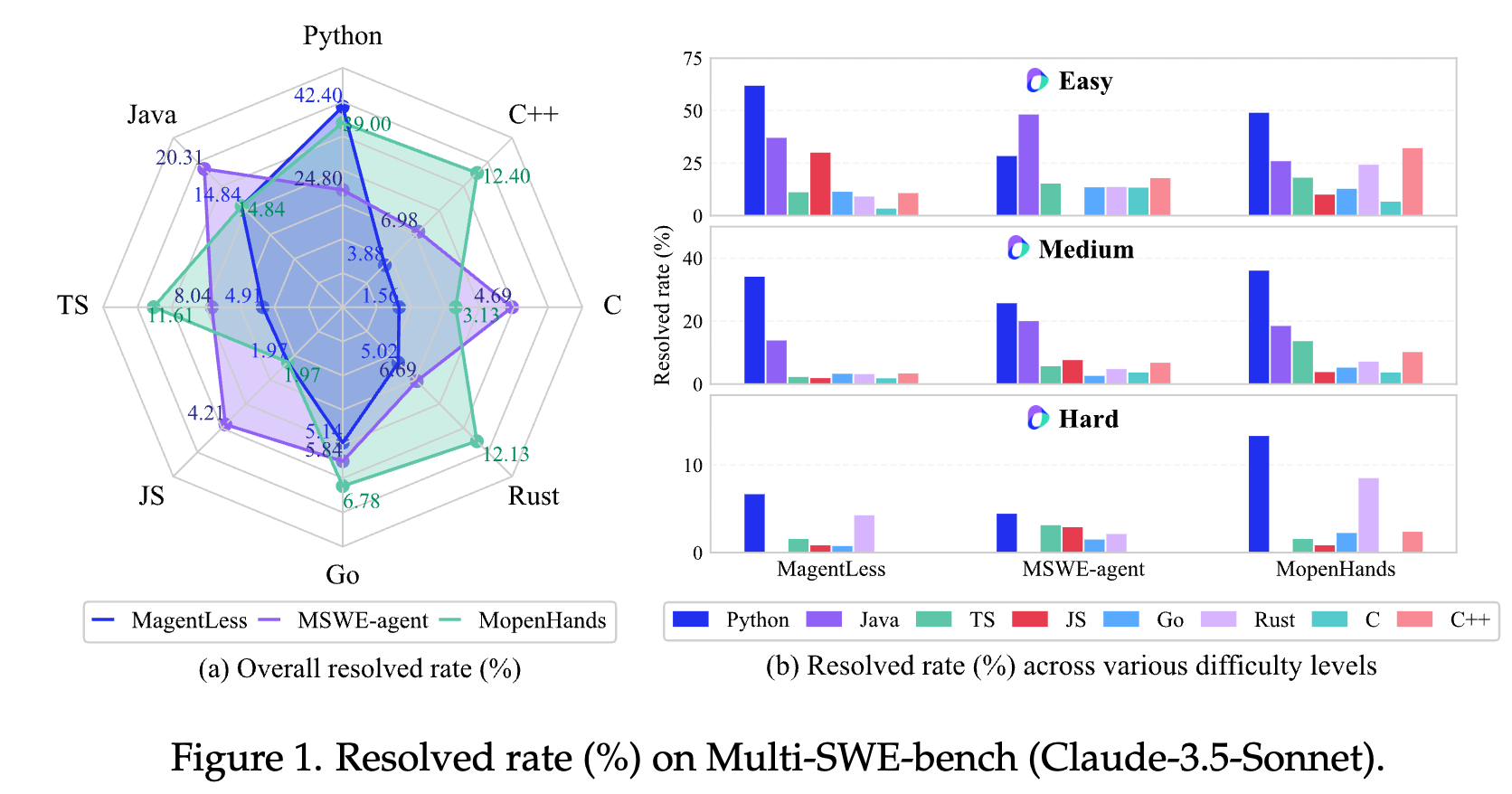
以上是字节发布的 Multi-SWE 数据集,它涵盖了不同的编程语言。可以发现,LLM 在 Python 上的表现远远好于其他语言,其次是 Java。这可以被解释为之前的 benchmark 大多是基于 Python 的,所以 LLM 对 Python 过拟合了。至于 Java,我能想到的一个解释是,Java 的语法非常固定,不同个体的代码风格差异非常小,所以 LLM 学到的表示非常稳定。
Thinking
三篇文章都是关于统一表示的
- ReCo希望消除代码风格的差异,比如有的人喜欢用 lambda function,有的人喜欢直接写递归。这在逻辑上不应该存在差异,但是在 embedding 上的确是不一样的。这是因为初始化的时候,embedding 就被训练到保留风格、逻辑等重要特性,后续的 finetune 本质上是在告诉检索器,代码风格不重要。没有太多的数据,是不足以推动检索器完全学到如何区分风格差异和逻辑差异的。
- UniCoder和IRCoder 关注到了另一个问题,编程语言的中间表示。可能在我看来,Unicoder的方法更好,这是因为,高级编程语言转换为汇编这个过程,要让LLM学到,其实不是一个很平凡的事情。但是学到高级编程语言和高级编程语言之间的转换,是一个更容易的事情。
或许我们可以探究,不同语法是如何影响 LLM 的能力的,到底是因为表示(预训练数据量的不同)?还是因为自由度(JavaScript在字节的benchmark里得分一般偏低,这或许是因为自由度过大)?
虽然 Copilot、Cursor 等工具现在已经表现出了非常强大的能力,但是我们明显能发现:
- 即使是同一个 LLM backend,不同编程助手之间的能力差异还是非常大的。 比如 Copilot 和 Cursor 虽然都是用的 Claude 3.7 Sonnet,但是由于代码检索实现的差异、工具链的实现以及 apply 模型的实现,其实表现还是非常不一样的。举个例子,在 Cursor 里,即使我没有明确提及某个文件,Cursor如果发现这个文件是可能有用的还是会去主动阅读它。这就是 RAG/GAR 实现上的差异了。再比如,Trae 的早期版本,apply 还经常容易替换到错误的位置。这提示我们,在 LLM backend 之外,还是有很广阔的空间去做后处理。
- 编程助手很难直接和产出的代码进行交互,需要人类去做 debugger。 另一个痛点是,编程助手很难直接和 enviroment 进行交互。当然现在也有一些论文尝试去做这件事情,基于强化学习的手段。不过我可能认为这做得些微复杂。实际上,我们可能只需要用 mcp 等工具,让LLM能够感知自己产出的代码的期望结果就好了,否则 LLM 只能通过「想象」。这也是为什么我认为在当前的技术下,编程助手实现后端是远简单于实现前端的,因为后端可以直接通过 cli 工具获得反馈。而前端还尚且缺乏比较好的手段。这也是我做 MCP-pptr 的初衷。
不过做的过程中就发现,要很好找到 LLM 需要的信息是一个非常 tricky 的事情。比如,我们担心 LLM 实现的样式不够准确,总是这里差 10px 那里差 5px,有几种做法。
直接截图网页给LLM 这几乎是最差的一种做法,因为 LLM 的特性就决定了它对这种细微的差异是不敏感的。
直接允许 LLM 执行 JavaScript 这种方法的优势是给了 LLM 极大的自由度,但是问题也在于此,解空间太大了。LLM 往往不知道需要调用这个工具,即使调用了,也只能象征性地执行一些代码,做不了实际的事情。
给 LLM 提供测量工具 这种方法的优势在于 LLM 能明确知道这个工具的用途。也是我认为最好的方法。
不过另一方面,LLM 缺乏对它的代码产生结果的直接感受。比如
import {
AlertDialog,
AlertDialogAction,
AlertDialogCancel,
AlertDialogContent,
AlertDialogDescription,
AlertDialogFooter,
AlertDialogHeader,
AlertDialogTitle,
AlertDialogTrigger,
} from "@/components/ui/alert-dialog"
import { Button } from "@/components/ui/button"
export function AlertDialogDemo() {
return (
<AlertDialog>
<AlertDialogTrigger asChild>
<Button variant="outline">Show Dialog</Button>
</AlertDialogTrigger>
<AlertDialogContent>
<AlertDialogHeader>
<AlertDialogTitle>Are you absolutely sure?</AlertDialogTitle>
<AlertDialogDescription>
This action cannot be undone. This will permanently delete your
account and remove your data from our servers.
</AlertDialogDescription>
</AlertDialogHeader>
<AlertDialogFooter>
<AlertDialogCancel>Cancel</AlertDialogCancel>
<AlertDialogAction>Continue</AlertDialogAction>
</AlertDialogFooter>
</AlertDialogContent>
</AlertDialog>
)
}
这段代码,LLM 是很难想象到它执行出来的 HTML backbone是什么样。因此,如何做代码层面的RAG/GAR/Prompt也是一个悬而未决的问题。